Top Lakera Guard Alternatives for LLM Security Guardrails
 Apr 17,2026
Apr 17,2026 By prasenjit.saha
By prasenjit.saha
If you’re searching for Lakera Guard alternatives, you’re probably in one of these situations:
You’re shipping an LLM feature (RAG chatbot, agent, copilot), security reviewed it, and someone asked, Cool… how do we stop prompt injection and data leaks? Or you already tried basic content filters, and your red team still got the model to ignore instructions using something hidden inside a document. That hidden-in-the-data pattern is exactly what Google describes as indirect prompt injection in complex, multi-source AI apps.
This guide is built to help you pick a realistic option based on deployment constraints, cloud stack, latency budget, and the threats that actually matter (OWASP’s LLM Top 10 is a good baseline).
Why do teams look for Lakera Guard alternatives?
Lakera Guard is positioned as a developer-first AI security layer that protects LLM applications, focusing on risks like prompt injection and data leakage. When you look at its documentation, it emphasizes daily-updated threat intelligence and operational needs like logs for compliance.
So why do people still search for alternatives? Because the best option depends on constraints that are painfully real in production:
Cloud-lock-in and native guardrails: If your GenAI workloads are already standardized on a single cloud, cloud-native guardrails can be easier to govern and easier to wire into platform controls.
Deployment model and privacy requirements: Some orgs require fully in-house deployment. A concrete example: Dropbox chose a solution that could run internally and was strict about latency, long-context performance, and confidence scoring.
Security scope: Prompt and response filtering is not the full story anymore. Indirect prompt injection can arrive via emails, documents, web pages, or tool outputs, sometimes without direct user text containing anything suspicious.
Governance and audit readiness: With regulatory milestones approaching (for example, the EU AI Act entering force in August 2024 and becoming fully applicable in stages, with major applicability dates in 2025–2027), security teams increasingly want audit trails, policy mapping, and risk oversight beyond a single runtime filter.
One more practical point: prompt injection is now widely treated as a top-tier risk category in LLM app security frameworks.AWS even explains it in a very familiar way: it’s an application-level security issue, often compared to SQL injection responsibility patterns.
The Best Lakera Guard Alternatives To Consider
A quick framing that helps avoid bad comparisons: some alternatives are direct replacements (runtime guardrails in the prompt path), while others are complements (red teaming, monitoring, governance). In practice, enterprises often deploy more than one layer.
Below is a buyer-friendly list that matches how modern frameworks describe the problem (OWASP) and how big platforms describe defenses (layered, continuous).
Dedicated LLM security platforms (best when you need model-agnostic, app-layer runtime controls)
1. Cygeniq HexaShield AI (Security for AI) + GRCortex AI (governance/risk)
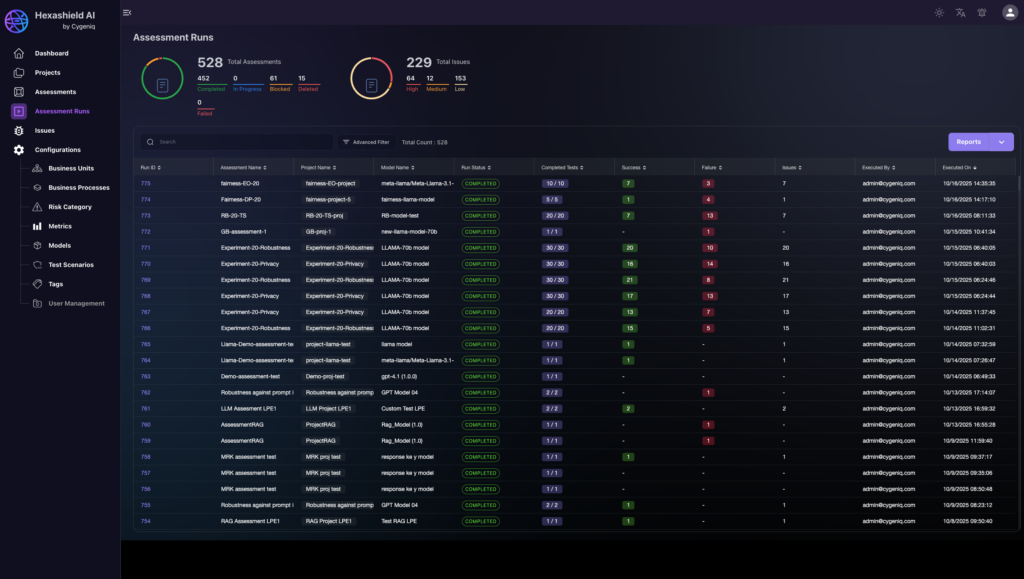
Cygeniq positions HexaShield AI as continuous testing and protection across models, data, prompts, agents, and APIs against adversarial attacks and misuse, and the broader platform emphasizes governance, monitoring, and risk management for regulated environments.
Why this can be the enterprise alternative angle: Many buyers searching for Lakera Guard alternatives actually need more than a runtime filter: they need auditability, policy enforcement, and risk traceability across the AI lifecycle and across agents/tools. That’s the core positioning of Cygeniq’s security for AI approach.
Pros: Broader than prompt filtering alone; covers prompt injection, risk scoring, compliance alignment, audit trails, and governance workflows; strong fit for regulated AI programs.
Cons: Not a lightweight plug-in purchase; likely better suited for enterprise programs than small teams.
2. Lasso Security
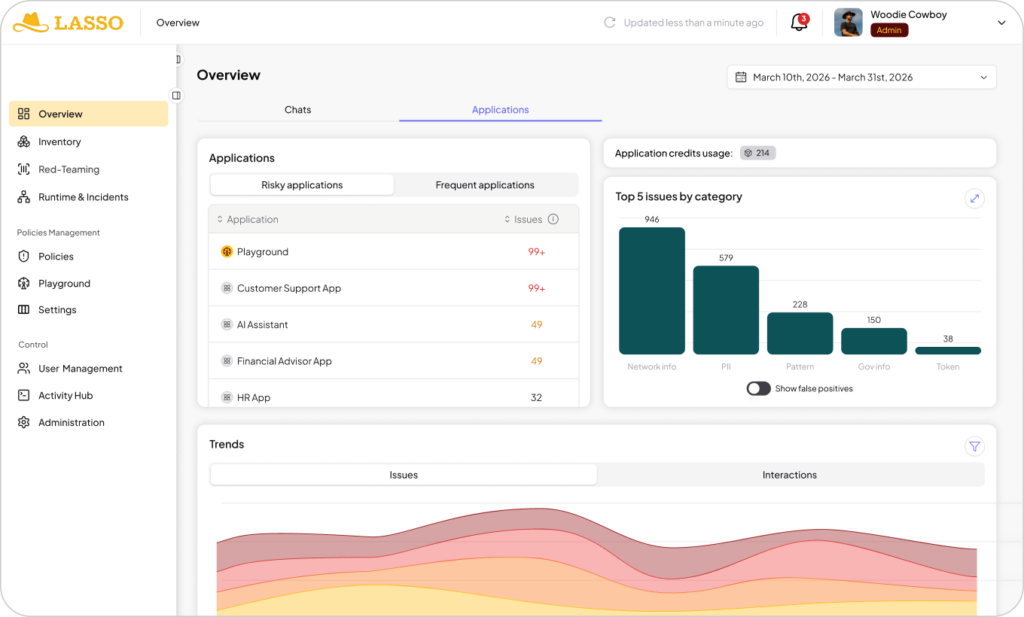
Lasso markets intent-based prompt injection protection, claiming real-time detection under a low-latency budget and emphasizing semantic/intent analysis beyond keyword filters.
Strong fit: agentic systems, chatbots, and workflows where you want configurable actions (block, alert, sanitize, guide users).
Pros: Markets strong speed and intent-based detection; good for agentic workflows and action policies.
Cons: Public enterprise pricing is not clearly listed, buyers may need a live evaluation to assess fit and TCO.
3. Prompt Security
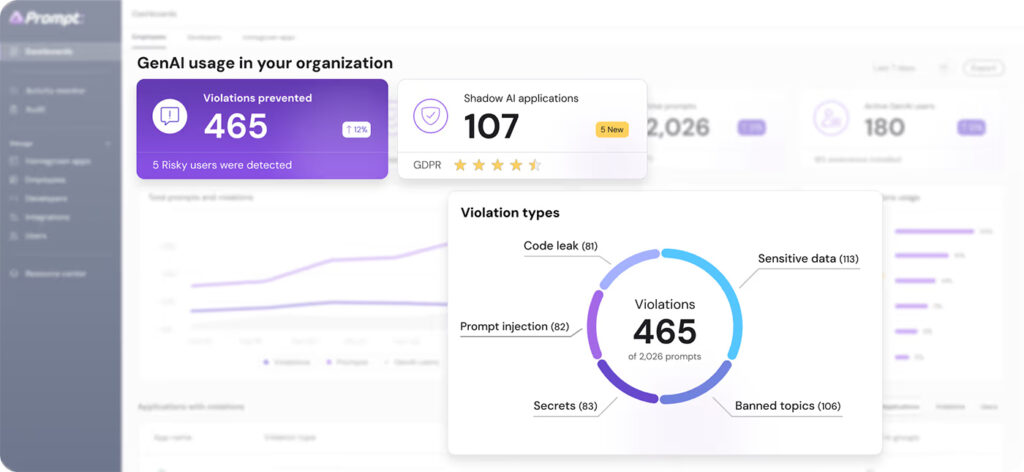
Prompt Security positions itself as an AI security company that secures GenAI across homegrown AI apps, code assistants, and agentic AI, including deployment as SaaS or self-hosted and offering AI red teaming.
Strong fit: orgs that need visibility and enforcement across multiple AI usage surfaces (apps + dev tooling + agents).
Pros: Broader platform scope than simple prompt filtering; supports cloud and self-hosted deployment.
Cons: Limited public pricing transparency; may be more platform-heavy than teams needing only a narrow runtime layer.
4. WhyLabs LLM Security
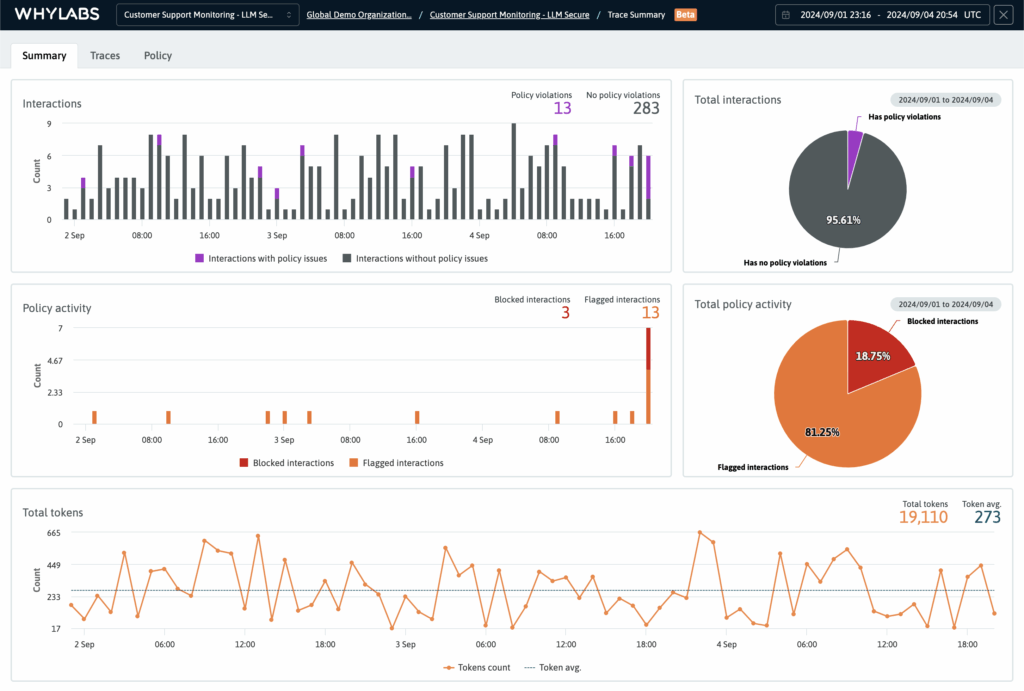
WhyLabs documentation emphasizes guarding LLMs with policy rulesets aligned to OWASP and MITRE ATLAS, and detecting issues like prompt injection and PII leakage, with observability via OpenLLMTelemetry.
Strong fit: teams that want security guardrails plus monitoring/telemetry rather than only block/allow decisions.
Pros: Strong observability angle; useful when you want monitoring plus policy controls, not just block/allow.
Cons: Less of a pure “drop-in Lakera replacement” if your main need is only runtime shielding.
5. F5 AI Guardrails (CalypsoAI lineage)
F5 positions AI Guardrails as runtime protection against threats like prompt injection and jailbreaks, with customizable policies.
Industry reporting also describes the acquisition-driven direction: combining runtime guardrails with red teaming and threat management for enterprise AI.
Pros: Enterprise-grade positioning for models, apps, agents, and data; fits organizations already using F5 security stack.
Cons: Pricing is not public, broader platform may be more than smaller teams need.
Cloud-native guardrails (best when you’re standardizing on one cloud)
Amazon Bedrock Guardrails
Best for AWS-first GenAI. It supports configurable safeguards like content filters (including prompt attack), denied topics, and sensitive information/PII controls, and AWS documentation explicitly recommends associating guardrails with agents and implementing prompt-injection protections.
When it’s a strong Lakera alternative: You’re all-in on Bedrock-hosted models and want guardrails that fit AWS governance patterns.
Watch-outs: Cloud-native guardrails can be excellent, but you may still need deeper app-level controls for RAG ingestion safety, tool-call policies, and cross-provider use cases.
Pros: Native AWS fit; content filters, denied topics, and sensitive info controls; easier governance inside AWS environments.
Cons: Best when you stay inside AWS; less ideal for multi-cloud or model-agnostic environments; may still need extra app-layer controls for RAG and tools.
Microsoft Prompt Shields (Azure AI Content Safety)
Best for Azure-first. Microsoft describes Prompt Shields as a unified API to detect and block adversarial prompt attacks on LLMs, including both user prompt attacks and document attacks (the indirect case).
Bonus option: Microsoft also has prompt injection protection at the network/SSE layer (Entra Global Secure Access AI Gateway), positioned as a way to enforce guardrails without code changes.
Pros: Strong for direct prompt attacks and document attacks; good fit for Azure AI Content Safety stack.
Cons: More cloud-tied than model-agnostic vendors; broader governance often needs other tools around it.
Open-source guardrails and red teaming (best for teams that want control and can invest engineering time)
NVIDIA NeMo Guardrails
NVIDIA describes NeMo Guardrails as a scalable solution/toolkit for orchestrating guardrails for agentic AI apps, including topic control, PII detection, jailbreak prevention, and RAG grounding.
Pros: Flexible, customizable, strong for agentic workflows, PII, topic control, grounding, and multilingual flows.
Cons: Requires engineering ownership; not a turnkey enterprise security platform by itself.
Guardrails AI
Guardrails describes itself as a Python framework that runs input/output guards to detect and mitigate risk types, and it’s widely used as an application-layer guardrails library.
Pros: Good developer control; rich validator ecosystem; useful for structured input/output controls.
Cons: More of a framework than a full enterprise security program; teams own more integration and ops work.
Meta Llama Guard
Llama Guard models are designed to classify prompts and responses for safety categories (content moderation style), and can be deployed self-hosted or via hosting platforms.
Pros: Useful building block for content safety classification; can be self-hosted.
Cons: Not a complete enterprise guardrails stack; needs orchestration, logging, policy, and tuning around it.
Protect AI LLM Guard
LLM Guard is positioned as a suite to detect, redact, and sanitize prompts and responses for safety, security, and compliance.
Pros: Strong building block for prompt/response sanitization; model-agnostic.
Cons: Still a toolkit, not a full control plane; enterprises usually need added governance and monitoring around it.
A reality check on “tool performance” (important if you’re buying for security outcomes)
Independent benchmarking shows that results vary widely depending on context, false positives, and latency tradeoffs. One evaluation on the Palit benchmark reports detailed metrics for multiple tools (including Lakera Guard, Azure Prompt Shield, CalypsoAI Moderator, and open-source tools), and highlights the classic trilemma: catching malicious prompts, keeping false positives down, and staying low-latency.
Comparison Table
| Platform | Category | Best fit | Deployment | Pricing |
| Cygeniq HexaShield AI + GRCortex AI | Custom/contact sales | Enterprises that need runtime protection plus governance, auditability, and policy mapping | SaaS, cloud, on-prem, hybrid | Custom / contact sales |
| Lakera Guard | Dedicated LLM runtime security | Teams that want developer-friendly prompt/response protection and operational logging | SaaS, enterprise plans available | Community plan free; enterprise custom |
| Amazon Bedrock Guardrails | Cloud-native guardrails | AWS-first teams using Bedrock models and agents | AWS managed service | Public usage-based pricing |
| Microsoft Prompt Shields | Cloud-native prompt attack defense | Azure-first teams, especially those worried about both direct and indirect prompt injection | Azure managed service | Public usage-based pricing page |
| Google Cloud Model Armor | Cloud-native runtime AI protection | Google Cloud / Vertex AI teams, or buyers wanting API and inline integrations | Google Cloud managed service | Public usage-based pricing |
| Lasso Security | Dedicated AI security/guardrails | Enterprises prioritizing low-latency intent-based prompt injection defense | SaaS/enterprise deployment options | Mostly custom/contact sales |
| Prompt Security | Dedicated AI security platform | Teams that want security across apps, copilots, dev tools, and agentic AI | SaaS or self-hosted | Mostly custom / contract-based |
| WhyLabs LLM Security | Guardrails + observability | Teams that want policy enforcement plus monitoring and telemetry | Cloud platform with open tooling | Trial/public entry, enterprise pricing unclear |
| F5 AI Guardrails | Enterprise runtime AI protection | Large enterprises wanting AI runtime protection tied to broader app/security infrastructure | Enterprise/hybrid | Custom / contact sales |
| NVIDIA NeMo Guardrails | Open-source guardrails toolkit | Teams that want programmable guardrails and can invest engineering effort | Self-hosted / open source; enterprise support via NVIDIA stack | Open source; enterprise support separate |
| Guardrails AI | Open-source/framework | Builders who want validators and app-layer guardrails across LLMs | Guardrails AI Open-source/framework Builders who want validators and app-layer guardrails across LLMs | Core framework positioning is open; paid platform details are not prominent |
| Meta Llama Guard | Open-weight safety classifier | Teams that need self-hosted prompt/response safety classification | Self-hosted / hosted by platform partners | Model access, no traditional SaaS list price |
| Protect AI LLM Guard | Open-source/toolkit | Teams that want scanners for detect-redact-sanitize workflows | Self-hosted / library / API options | Open toolkit; enterprise pricing not clearly public |
How to choose and deploy a guardrails stack
If you remember only one thing, don’t treat this as a “single tool purchase.” Treat it like designing a layered security control plane for LLM apps.
Google’s security team describes indirect prompt injection as an evolving threat and emphasizes continuous discovery + testing + defense refinement. Cisco makes a similar point in its industry guidance – you need to distinguish between direct and indirect injection because the threat model changes your defense.
Here’s a practical way to choose (using real selection criteria seen in large deployments):
Start with your non-negotiables
– Deployment constraints: SaaS-only vs self-hosted vs hybrid (Dropbox required in-house deployability).
– Latency budget and long-context behavior: Attacker payloads often hide in long context windows; Dropbox explicitly calls out long context performance and strict latency budgets.
– Coverage mapped to OWASP: Prompt injection, sensitive info disclosure, insecure output handling, excessive agency/tool risk, etc.
Build the reference architecture (what “good” looks like)
– Pre-processing layer: Validate/sanitize user prompts and system prompts; apply prompt attack detection and PII rules.
– Context ingestion safety for RAG: Scan retrieved documents/content for instruction smuggling (this is where indirect injection lives). Microsoft explicitly treats document attacks as part of prompt shielding, and Google documents indirect injection as a core threat vector.
– Tool-call and agent controls: If your agent can call tools, you need policy boundaries and auditability for those actions (OWASP risk lists and multiple vendor architectures highlight this shift to agentic risk).
– Post-processing layer: Output filters, sensitive data redaction, and safe rendering/encoding (OWASP highlights insecure output handling as a major category).
– Telemetry + continuous testing: Log guardrail decisions, run red teaming/vulnerability scans (tools like Garak), and treat it like an ongoing program.
Don’t ignore compliance and governance requirements:
Even if you’re “just building a chatbot,” governance pressure is increasing. The EU AI Act entered into force in August 2024 and has staged applicability (including key obligations becoming applicable in 2025–2027).
Standards such as the NIST AI RMF (released in January 2023) and ISO/IEC 42001 (published in December 2023) push organizations toward structured risk management, controls, and continuous improvement.
Where Cygeniq fits in a Lakera alternative decision.
If your real requirement is enterprise-grade security + risk + auditability across models, prompts, agents, and APIs, Cygeniq positions itself exactly in that “operating layer” space: securing AI systems, governing them, and managing risk exposure across the lifecycle.
Conclusion
Keeping LLM apps useful while stopping prompt attacks, data leakage, and unsafe agent behavior. OWASP frames prompt injection as a top risk, and both cloud providers and security teams now treat indirect injection as an evolving, continuous challenge.
If you want a cloud-native default, start with Bedrock Guardrails / Prompt Shields / Model Armor based on your primary cloud.
If you need a model-agnostic layer across apps, agents, and APIs (plus governance and auditability), that’s where platforms like Cygeniq’s HexaShield AI and GRCortex AI are designed to fit. If your team is evaluating Lakera Guard alternatives because you need enterprise AI security that covers prompts, models, agents, APIs, and audit-ready governance, book a Cygeniq demo and map your current AI attack surface to a practical layered control plan.
Frequently Asked Questions
What is Lakera Guard used for?
Lakera Guard is positioned as a runtime security layer for LLM applications, focusing on prompt attacks (including direct/indirect prompt injection), data leakage prevention, and unsafe interactions, delivered as an API and with operational logging.
What’s the best Lakera Guard alternative for AWS-first teams?
Amazon Bedrock Guardrails is the natural first place to look if your LLM apps and agents are built around Bedrock, because it provides guardrails components like content filters (including prompt attack), topic controls, and sensitive information filters/PII-style protections.
What’s the best Lakera Guard alternative for Azure-first teams?
Microsoft’s Prompt Shields (Azure AI Content Safety) and Cygeniq’s HexaShield AI and GRCortex AI are purpose-built to detect adversarial user prompt attacks and document attacks (the indirect scenario), making it relevant when your threat model includes retrieved documents and tool outputs.
Are open-source Lakera Guard alternatives “good enough” for production?
They can be, but you’ll usually trade license cost for engineering time and operational maturity. Open-source frameworks like NeMo Guardrails and Guardrails AI provide strong building blocks, while open-source scanners like Garak help with red teaming. You still need careful tuning, logging, and continuous evaluation to manage false positives/negatives and evolving attacks.
How do you prevent prompt injection in a RAG chatbot?
You need layered defenses: prompt validation and shielding, scanning retrieved documents for hidden instructions (indirect injection), constraining tool permissions, and output handling controls. OWASP’s cheat sheet and Google’s security guidance both reinforce that injection is a systemic risk that needs defense-in-depth, not a single regex filter.